Automating Email Attachment Analysis: How AWS Glue and Redshift Can Help Businesses Make Better Use of Valuable Data
- Dima Hamed
- April 27, 2023
- 9:00 am
Share the Blog
As businesses grow, so does the amount of data generated. One source of data that is often overlooked is email attachments. Email attachments can contain valuable data that can be analyzed and used to improve business operations.
Assuming that you work for a company that receives a large volume of customer support emails containing various attachments such as PDFs, images, or CSV files, your company would want to store all these attachments in an S3 bucket for long-term archival and analysis purposes and be able to query the contents of these attachments in real-time to improve customer service. Extracting data from email attachments manually can be time-consuming and error-prone. Fortunately, a solution can automate this process using Amazon Web Services (AWS).
In this article, we’ll demonstrate how to automatically upload email attachments to S3 and then load them into Redshift for further analysis.
Automating Email Attachments with Zapier & AWS Glue
To automate uploading received attachments in emails, you can use Zapier to create a workflow that triggers whenever a new email with an attachment is received in your company’s support email inbox. Zapier can automatically extract the attachment(s) from the email and upload them to your company’s S3 bucket. You can set up a filter in Zapier to ensure that only emails with relevant attachments are processed.
Once the attachments are uploaded to S3, you can use AWS Glue to load the data from the attachments into your company’s Redshift data warehouse. Glue can automatically detect the schema of the uploaded files and create a corresponding data catalog in Glue. You can then set up Glue jobs to extract and transform the data from the attachments and load it into Redshift.
In general, the solution consists of five main components:
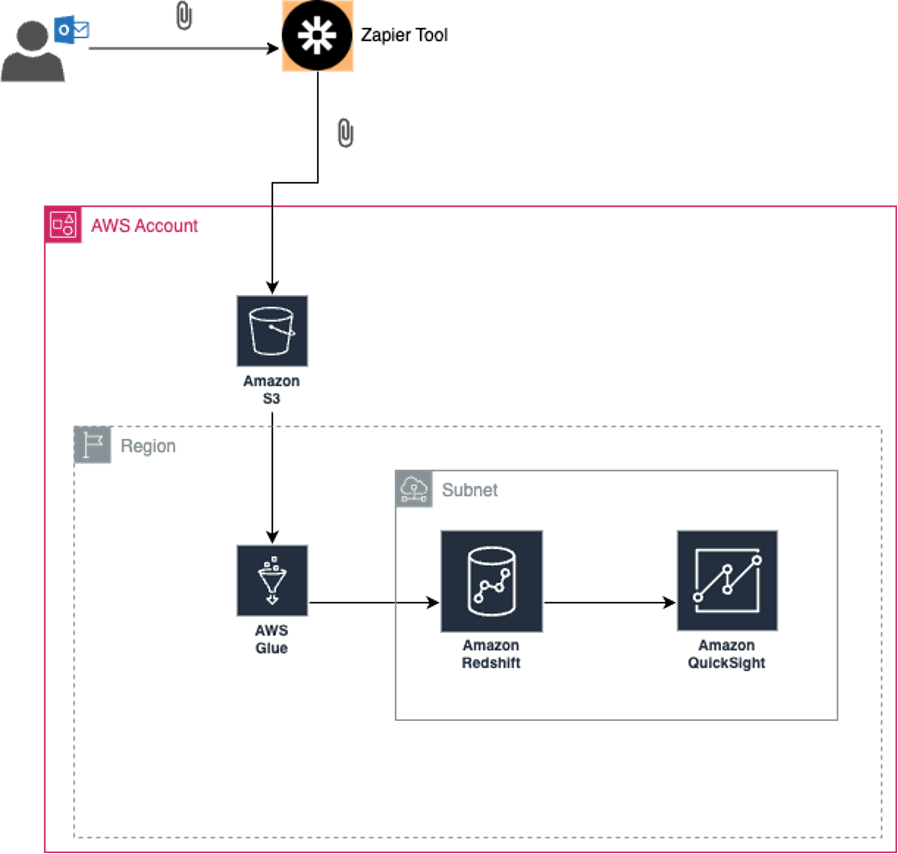
Zapier tool
An automation tool that connects your email accpunt to your S3 bucket
S3
An object storage service that stores email attachments.
AWS Glue
A serverless data integration service (for ETL) that extracts and loads data from S3 to Redshift.
aws redshift
A fully managed, petabyte-scale data warehouse service in the cloud
aws quicksight
Cloud-powered business intelligence service that delivers insights to an organization.
Email Attachments extraction to S3
The first step is to set up a Zapier account and create a Zap that connects your email account and S3 bucket. A Zap is a workflow that automates tasks between two or more apps. In this case, we’ll use Zapier to automatically send any email attachments to our S3 bucket. Zapier can be configured to extract attachments from specific emails by applying some specific selection rule based on email location, keywords, sender, etc.
Zapier will trigger periodic checks of the email to extract all attachments needed and upload them to S3.
Loading attachment files to Redshift
The next step is to create a Glue crawler to discover the data in your S3 bucket. A crawler is a program that scans your data sources and creates a table schema that matches the structure of your data.
Before you can create a Glue crawler, you need to create a Glue database to store the metadata for your data sources.
Now that you have a Glue crawler to discover the data in your S3 bucket, you can use extract and load the data into Redshift. This is done using Glue jobs, which are Python scripts that you can run on-demand or on a schedule.
Next, you must configure the Python script to extract and transform your data. This script will read data from your S3 bucket, transform it into the required format, and load it into Redshift.
After that, you are ready to Run the Glue Job to extract and load your data into Redshift.
Once you run the Glue job, it will extract the data from your S3 bucket, transform it according to your script, and load it into your Redshift cluster. You can monitor the progress of the job using the Glue console.
Once the job is complete, you can view the data in your Redshift table using your preferred SQL client. You can also schedule the Glue job to run regularly to ensure that your Redshift data is always up to date with the data in your S3 bucket.
Once the data reach redshift you can work on transforming, cleansing, and re-modeling the data to be ready for analysis using QuickSight.
Automated solutions to Improve Business Operations
With this solution, we can automate the process of extracting attachments from received emails, storing them in S3, and loading them into Redshift. This can help you streamline your data processing workflows and make better use of your data as you can easily store and analyze customer support attachments in a centralized location, enabling faster query response times and better customer service overall.
